Browse Source
adding sparsepp as a 3rd-party resource
adding sparsepp as a 3rd-party resource
Former-commit-id:main3c449a54e0[formerlyf850f7a71d] Former-commit-id:e788f974c5
8 changed files with 9432 additions and 0 deletions
-
36resources/3rdparty/sparsepp/LICENSE
-
288resources/3rdparty/sparsepp/README.md
-
221resources/3rdparty/sparsepp/bench.md
-
47resources/3rdparty/sparsepp/docs/.gitignore
-
11resources/3rdparty/sparsepp/makefile
-
5626resources/3rdparty/sparsepp/sparsepp.h
-
2923resources/3rdparty/sparsepp/spp_test.cc
-
280resources/3rdparty/sparsepp/spp_utils.h
@ -0,0 +1,36 @@ |
|||||
|
// ---------------------------------------------------------------------- |
||||
|
// Copyright (c) 2016, Gregory Popovitch - greg7mdp@gmail.com |
||||
|
// All rights reserved. |
||||
|
// |
||||
|
// This work is derived from Google's sparsehash library |
||||
|
// |
||||
|
// Copyright (c) 2005, Google Inc. |
||||
|
// All rights reserved. |
||||
|
// |
||||
|
// Redistribution and use in source and binary forms, with or without |
||||
|
// modification, are permitted provided that the following conditions are |
||||
|
// met: |
||||
|
// |
||||
|
// * Redistributions of source code must retain the above copyright |
||||
|
// notice, this list of conditions and the following disclaimer. |
||||
|
// * Redistributions in binary form must reproduce the above |
||||
|
// copyright notice, this list of conditions and the following disclaimer |
||||
|
// in the documentation and/or other materials provided with the |
||||
|
// distribution. |
||||
|
// * Neither the name of Google Inc. nor the names of its |
||||
|
// contributors may be used to endorse or promote products derived from |
||||
|
// this software without specific prior written permission. |
||||
|
// |
||||
|
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS |
||||
|
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT |
||||
|
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR |
||||
|
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT |
||||
|
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, |
||||
|
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT |
||||
|
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, |
||||
|
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY |
||||
|
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT |
||||
|
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE |
||||
|
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. |
||||
|
// ---------------------------------------------------------------------- |
||||
|
|
||||
@ -0,0 +1,288 @@ |
|||||
|
[](https://travis-ci.org/greg7mdp/sparsepp) |
||||
|
|
||||
|
# Sparsepp: A fast, memory efficient hash map for C++ |
||||
|
|
||||
|
Sparsepp is derived from Google's excellent [sparsehash](https://github.com/sparsehash/sparsehash) implementation. It aims to achieve the following objectives: |
||||
|
|
||||
|
- A drop-in alternative for unordered_map and unordered_set. |
||||
|
- **Extremely low memory usage** (typically about one byte overhead per entry). |
||||
|
- **Very efficient**, typically faster than your compiler's unordered map/set or Boost's. |
||||
|
- **C++11 support** (if supported by compiler). |
||||
|
- **Single header** implementation - just copy `sparsepp.h` to your project and include it. |
||||
|
- **Tested** on Windows (vs2010-2015, g++), linux (g++, clang++) and MacOS (clang++). |
||||
|
|
||||
|
We believe Sparsepp provides an unparalleled combination of performance and memory usage, and will outperform your compiler's unordered_map on both counts. Only Google's `dense_hash_map` is consistently faster, at the cost of much greater memory usage (especially when the final size of the map is not known in advance). |
||||
|
|
||||
|
For a detailed comparison of various hash implementations, including Sparsepp, please see our [write-up](bench.md). |
||||
|
|
||||
|
## Example |
||||
|
|
||||
|
```c++ |
||||
|
#include <iostream> |
||||
|
#include <string> |
||||
|
#include <sparsepp.h> |
||||
|
|
||||
|
using spp::sparse_hash_map; |
||||
|
|
||||
|
int main() |
||||
|
{ |
||||
|
// Create an unordered_map of three strings (that map to strings) |
||||
|
sparse_hash_map<std::string, std::string> email = |
||||
|
{ |
||||
|
{ "tom", "tom@gmail.com"}, |
||||
|
{ "jeff", "jk@gmail.com"}, |
||||
|
{ "jim", "jimg@microsoft.com"} |
||||
|
}; |
||||
|
|
||||
|
// Iterate and print keys and values |
||||
|
for (const auto& n : email) |
||||
|
std::cout << n.first << "'s email is: " << n.second << "\n"; |
||||
|
|
||||
|
// Add a new entry |
||||
|
email["bill"] = "bg@whatever.com"; |
||||
|
|
||||
|
// and print it |
||||
|
std::cout << "bill's email is: " << email["bill"] << "\n"; |
||||
|
|
||||
|
return 0; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
## Installation |
||||
|
|
||||
|
Since the full Sparsepp implementation is contained in a single header file `sparsepp.h`, the installation consist in copying this header file wherever it will be convenient to include in your project(s). |
||||
|
|
||||
|
Optionally, a second header file `spp_utils.h` is provided, which implements only the spp::hash_combine() functionality. This is useful when we want to specify a hash function for a user-defined class in an header file, without including the full `sparsepp.h` header (this is demonstrated in [example 2](#example-2---providing-a-hash-function-for-a-user-defined-class) below). |
||||
|
|
||||
|
## Usage |
||||
|
|
||||
|
As shown in the example above, you need to include the header file: `#include <sparsepp.h>` |
||||
|
|
||||
|
This provides the implementation for the following classes: |
||||
|
|
||||
|
```c++ |
||||
|
namespace spp |
||||
|
{ |
||||
|
template <class Key, |
||||
|
class T, |
||||
|
class HashFcn = spp_hash<Key>, |
||||
|
class EqualKey = std::equal_to<Key>, |
||||
|
class Alloc = libc_allocator_with_realloc<std::pair<const Key, T>>> |
||||
|
class sparse_hash_map; |
||||
|
|
||||
|
template <class Value, |
||||
|
class HashFcn = spp_hash<Value>, |
||||
|
class EqualKey = std::equal_to<Value>, |
||||
|
class Alloc = libc_allocator_with_realloc<Value>> |
||||
|
class sparse_hash_set; |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
These classes provide the same interface as std::unordered_map and std::unordered_set, with the following differences: |
||||
|
|
||||
|
- Calls to erase() may invalidate iterators. However, conformant to the C++11 standard, the position and range erase functions return an iterator pointing to the position immediately following the last of the elements erased. This makes it easy to traverse a sparse hash table and delete elements matching a condition. For example to delete odd values: |
||||
|
|
||||
|
```c++ |
||||
|
for (auto it = c.begin(); it != c.end(); ) |
||||
|
if (it->first % 2 == 1) |
||||
|
it = c.erase(it); |
||||
|
else |
||||
|
++it; |
||||
|
``` |
||||
|
|
||||
|
- Since items are not grouped into buckets, Bucket APIs have been adapted: `max_bucket_count` is equivalent to `max_size`, and `bucket_count` returns the sparsetable size, which is normally at least twice the number of items inserted into the hash_map. |
||||
|
|
||||
|
## Example 2 - providing a hash function for a user-defined class |
||||
|
|
||||
|
In order to use a sparse_hash_set or sparse_hash_map, a hash function should be provided. Even though a the hash function can be provided via the HashFcn template parameter, we recommend injecting a specialization of `std::hash` for the class into the "std" namespace. For example: |
||||
|
|
||||
|
```c++ |
||||
|
#include <iostream> |
||||
|
#include <functional> |
||||
|
#include <string> |
||||
|
#include "sparsepp.h" |
||||
|
|
||||
|
using std::string; |
||||
|
|
||||
|
struct Person |
||||
|
{ |
||||
|
bool operator==(const Person &o) const |
||||
|
{ return _first == o._first && _last == o._last; } |
||||
|
|
||||
|
string _first; |
||||
|
string _last; |
||||
|
}; |
||||
|
|
||||
|
namespace std |
||||
|
{ |
||||
|
// inject specialization of std::hash for Person into namespace std |
||||
|
// ---------------------------------------------------------------- |
||||
|
template<> |
||||
|
struct hash<Person> |
||||
|
{ |
||||
|
std::size_t operator()(Person const &p) const |
||||
|
{ |
||||
|
std::size_t seed = 0; |
||||
|
spp::hash_combine(seed, p._first); |
||||
|
spp::hash_combine(seed, p._last); |
||||
|
return seed; |
||||
|
} |
||||
|
}; |
||||
|
} |
||||
|
|
||||
|
int main() |
||||
|
{ |
||||
|
// As we have defined a specialization of std::hash() for Person, |
||||
|
// we can now create sparse_hash_set or sparse_hash_map of Persons |
||||
|
// ---------------------------------------------------------------- |
||||
|
spp::sparse_hash_set<Person> persons = { { "John", "Galt" }, |
||||
|
{ "Jane", "Doe" } }; |
||||
|
for (auto& p: persons) |
||||
|
std::cout << p._first << ' ' << p._last << '\n'; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
The `std::hash` specialization for `Person` combines the hash values for both first and last name using the convenient spp::hash_combine function, and returns the combined hash value. |
||||
|
|
||||
|
spp::hash_combine is provided by the header `sparsepp.h`. However, class definitions often appear in header files, and it is desirable to limit the size of headers included in such header files, so we provide the very small header `spp_utils.h` for that purpose: |
||||
|
|
||||
|
```c++ |
||||
|
#include <string> |
||||
|
#include "spp_utils.h" |
||||
|
|
||||
|
using std::string; |
||||
|
|
||||
|
struct Person |
||||
|
{ |
||||
|
bool operator==(const Person &o) const |
||||
|
{ |
||||
|
return _first == o._first && _last == o._last && _age == o._age; |
||||
|
} |
||||
|
|
||||
|
string _first; |
||||
|
string _last; |
||||
|
int _age; |
||||
|
}; |
||||
|
|
||||
|
namespace std |
||||
|
{ |
||||
|
// inject specialization of std::hash for Person into namespace std |
||||
|
// ---------------------------------------------------------------- |
||||
|
template<> |
||||
|
struct hash<Person> |
||||
|
{ |
||||
|
std::size_t operator()(Person const &p) const |
||||
|
{ |
||||
|
std::size_t seed = 0; |
||||
|
spp::hash_combine(seed, p._first); |
||||
|
spp::hash_combine(seed, p._last); |
||||
|
spp::hash_combine(seed, p._age); |
||||
|
return seed; |
||||
|
} |
||||
|
}; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
## Example 3 - serialization |
||||
|
|
||||
|
sparse_hash_set and sparse_hash_map can easily be serialized/unserialized to a file or network connection. |
||||
|
This support is implemented in the following APIs: |
||||
|
|
||||
|
```c++ |
||||
|
template <typename Serializer, typename OUTPUT> |
||||
|
bool serialize(Serializer serializer, OUTPUT *stream); |
||||
|
|
||||
|
template <typename Serializer, typename INPUT> |
||||
|
bool unserialize(Serializer serializer, INPUT *stream); |
||||
|
``` |
||||
|
|
||||
|
The following example demontrates how a simple sparse_hash_map can be written to a file, and then read back. The serializer we use read and writes to a file using the stdio APIs, but it would be equally simple to write a serialized using the stream APIS: |
||||
|
|
||||
|
```c++ |
||||
|
#include <cstdio> |
||||
|
|
||||
|
#include "sparsepp.h" |
||||
|
|
||||
|
using spp::sparse_hash_map; |
||||
|
using namespace std; |
||||
|
|
||||
|
class FileSerializer |
||||
|
{ |
||||
|
public: |
||||
|
// serialize basic types to FILE |
||||
|
// ----------------------------- |
||||
|
template <class T> |
||||
|
bool operator()(FILE *fp, const T& value) |
||||
|
{ |
||||
|
return fwrite((const void *)&value, sizeof(value), 1, fp) == 1; |
||||
|
} |
||||
|
|
||||
|
template <class T> |
||||
|
bool operator()(FILE *fp, T* value) |
||||
|
{ |
||||
|
return fread((void *)value, sizeof(*value), 1, fp) == 1; |
||||
|
} |
||||
|
|
||||
|
// serialize std::string to FILE |
||||
|
// ----------------------------- |
||||
|
bool operator()(FILE *fp, const string& value) |
||||
|
{ |
||||
|
const size_t size = value.size(); |
||||
|
return (*this)(fp, size) && fwrite(value.c_str(), size, 1, fp) == 1; |
||||
|
} |
||||
|
|
||||
|
bool operator()(FILE *fp, string* value) |
||||
|
{ |
||||
|
size_t size; |
||||
|
if (!(*this)(fp, &size)) |
||||
|
return false; |
||||
|
char* buf = new char[size]; |
||||
|
if (fread(buf, size, 1, fp) != 1) |
||||
|
{ |
||||
|
delete [] buf; |
||||
|
return false; |
||||
|
} |
||||
|
new (value) string(buf, (size_t)size); |
||||
|
delete[] buf; |
||||
|
return true; |
||||
|
} |
||||
|
|
||||
|
// serialize std::pair<const A, B> to FILE - needed for maps |
||||
|
// --------------------------------------------------------- |
||||
|
template <class A, class B> |
||||
|
bool operator()(FILE *fp, const std::pair<const A, B>& value) |
||||
|
{ |
||||
|
return (*this)(fp, value.first) && (*this)(fp, value.second); |
||||
|
} |
||||
|
|
||||
|
template <class A, class B> |
||||
|
bool operator()(FILE *fp, std::pair<const A, B> *value) |
||||
|
{ |
||||
|
return (*this)(fp, (A *)&value->first) && (*this)(fp, &value->second); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
int main(int argc, char* argv[]) |
||||
|
{ |
||||
|
sparse_hash_map<string, int> age{ { "John", 12 }, {"Jane", 13 }, { "Fred", 8 } }; |
||||
|
|
||||
|
// serialize age hash_map to "ages.dmp" file |
||||
|
FILE *out = fopen("ages.dmp", "wb"); |
||||
|
age.serialize(FileSerializer(), out); |
||||
|
fclose(out); |
||||
|
|
||||
|
sparse_hash_map<string, int> age_read; |
||||
|
|
||||
|
// read from "ages.dmp" file into age_read hash_map |
||||
|
FILE *input = fopen("ages.dmp", "rb"); |
||||
|
age_read.unserialize(FileSerializer(), input); |
||||
|
fclose(input); |
||||
|
|
||||
|
// print out contents of age_read to verify correct serialization |
||||
|
for (auto& v : age_read) |
||||
|
printf("age_read: %s -> %d\n", v.first.c_str(), v.second); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
|
||||
|
|
||||
@ -0,0 +1,221 @@ |
|||||
|
# Improving on Google's excellent Sparsehash |
||||
|
|
||||
|
[tl;dr] |
||||
|
|
||||
|
1. Looking for a great hash map |
||||
|
2. Google Sparsehash: brilliant idea, sparse version a bit slow and dated |
||||
|
3. Introducing Sparsepp: fast, memory efficient, C++11, single header |
||||
|
|
||||
|
|
||||
|
### Hashtables, sparse and dense, maps and btrees - Memory usage |
||||
|
|
||||
|
First, let's compare two separate versions of std::unordered_map, from Boost and g++ (the test was done using Boost version 1.55 and g++ version 4.8.4 on Ubuntu 14.02, running on a VM with 5.8GB of total memory space (under VirtualBox), 5.7GB free before benchmarks. For all tests that follow, hash entries were inserted in an initially empty, default sized container, without calling resize to preallocate the necessary memory. The code for the benchmarks is listed at the end of this article. |
||||
|
|
||||
|
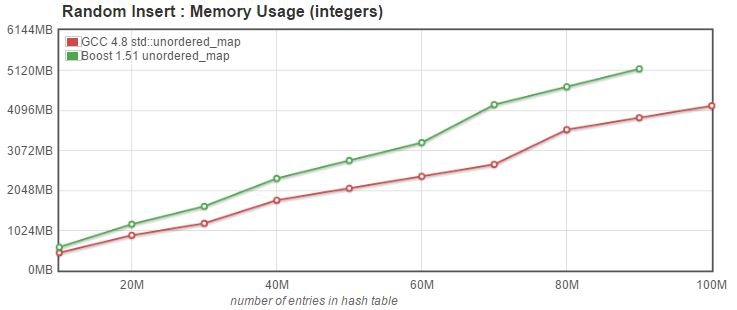
The graph below shows the memory usage when inserting `std::pair<uint64_t, uint64_t>` into the unordered_map. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
With this test, we see that Boost's implementation uses significantly more memory that the g++ version, and indeed it is unable to insert 100 Million entries into the map without running out of memory. Since the pairs we insert into the map are 16 bytes each, the minimum expected memory usage would be 1.6 GB. We see on the graph that g++ needs just a hair over 4 GB. |
||||
|
|
||||
|
Now, let's add to the comparison Google's offerings: the [Sparsehash](https://github.com/sparsehash/sparsehash) and [cpp-btree](https://code.google.com/archive/p/cpp-btree/) libraries. |
||||
|
|
||||
|
The [Sparsehash](https://github.com/sparsehash/sparsehash) library is a header-only library, open-sourced by Google in 2005. It offers two separate hash map implementations with very different performance characteristics. sparse_hash_map is designed to use as little memory as possible, at the expense of speed if necessary. dense_hash_map is extremely fast, but gobbles memory. |
||||
|
|
||||
|
The [cpp-btree](https://code.google.com/archive/p/cpp-btree/) library was open-sourced by Google in 2013. Although not a hash map, but a map storing ordered elements, I thought it would be interesting to include it because it claims low memory usage, and good performance thanks to cache friendliness. |
||||
|
|
||||
|
|
||||
|
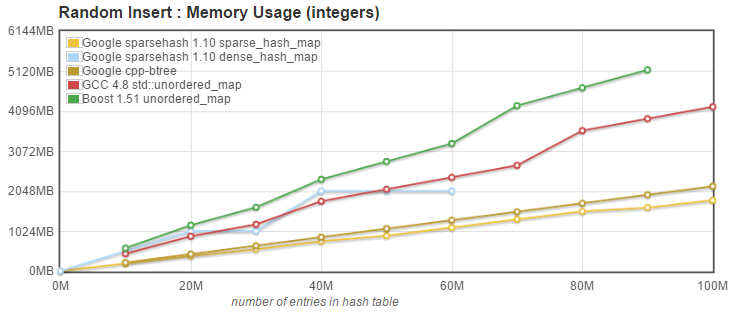 |
||||
|
|
||||
|
So what do we see here? |
||||
|
|
||||
|
Google's dense_hash_map (blue curve) was doing well below 60 Million entries, using an amount of memory somewhat in between the Boost and g++ unordered_map implementations, but ran out of memory when trying to insert 70 Million entries. |
||||
|
|
||||
|
This is easily understood because Google's dense_hash_map stores all the entries in a large contiguous array, and resizes the array by doubling its size when the array is 50% full. |
||||
|
|
||||
|
For 40M to 60M elements, the dense_hash_map used 2GB. Indeed, 60M entries, each 16 byte in size, would occupy 960Mb. So 70M entries would require over 50% of 2GB, causing a resize to 4Gb. And when the resize occurs, a total of 6GB is allocated, as the entries have to be transferred from the 2GB array to the 4GB array. |
||||
|
|
||||
|
So we see that the dense_hash_map has pretty dramatic spikes in memory usage when resizing, equal to six times the space required for the actual entries. For big data cases, and unless the final size of the container can be accurately predicted and the container sized appropriately, the memory demands of dense_hash_map when resizing may remove it from consideration for many applications. |
||||
|
|
||||
|
On the contrary, both Google's sparse_hash_map and btree_map (from cpp-btree) have excellent memory usage characteristics. The sparse_hash_map, as promised, has a very small overhead (it uses about 1.9GB, just 18% higher than the theorical minimum 1.6GB). The btree_map uses a little over 2GB, still excellent. |
||||
|
|
||||
|
Interestingly, the memory usage of both sparse_hash_map and btree_map increases regularly without significant spikes when resizing, which allows them to grow gracefully and use all the memory available. |
||||
|
|
||||
|
The two std::unordered_map implementations do have memory usage spikes when resizing, but less drastic than Google's dense_hash_map. This is because std::unordered_map implementations typically implement the hash map as an array of buckets (all entries with the same hash value go into the same bucket), and buckets store entries into something equivalent to a std::forward_list. So, when resizing, while the bucket array has to be reallocated, the actual map entries can be moved to their new bucket without requiring extra memory. |
||||
|
|
||||
|
|
||||
|
### What about performance? |
||||
|
|
||||
|
Memory usage is one thing, but we also need efficient containers allowing fast insertion and lookup. We ran series of three benchmarks, still using the same `std::pair<uint64_t, uint64_t>` value_type. While randomized, the sequence of keys was the same for each container tested. |
||||
|
|
||||
|
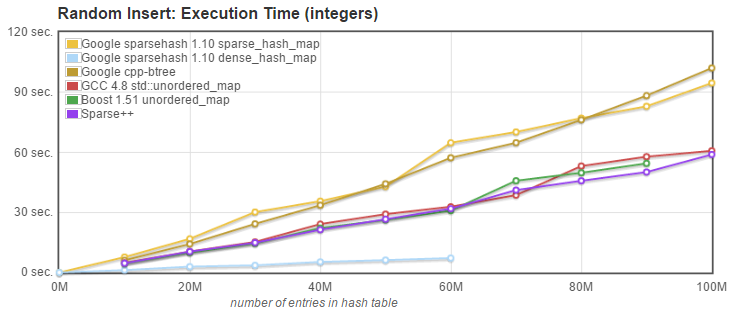
1. Random Insert: we measured the time needed to insert N entries into an initially empty, default sized container, without calling resize to preallocate the necessary memory. Keys were inserted in random order, i.e. the integer keys were not sorted. |
||||
|
API used: `pair<iterator,bool> insert(const value_type& val);` |
||||
|
|
||||
|
|
||||
|
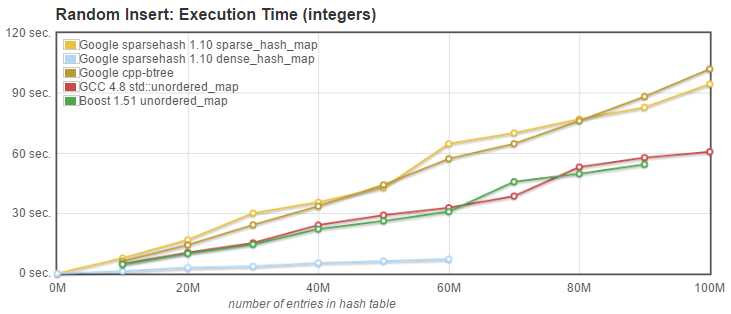 |
||||
|
|
||||
|
|
||||
|
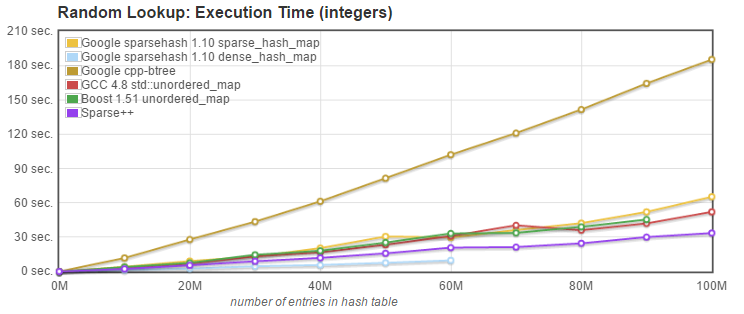
2. Random Lookup: we measured the time needed to retrieve N entries known to be present in the array, plus N entries with only a 10% probablility to be present. |
||||
|
API used: `iterator find(const key_type& k);` |
||||
|
|
||||
|
|
||||
|
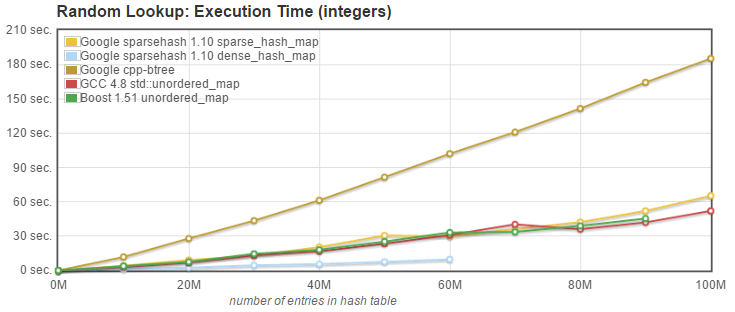 |
||||
|
|
||||
|
|
||||
|
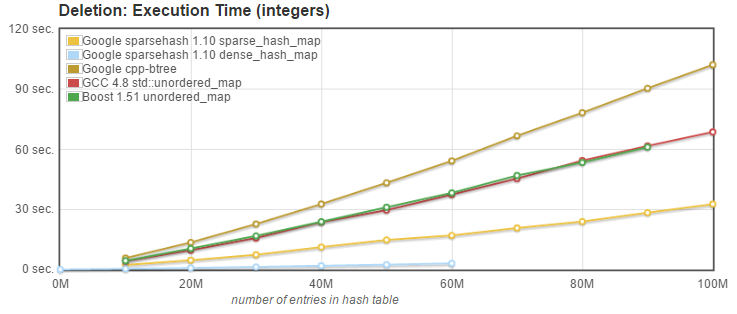
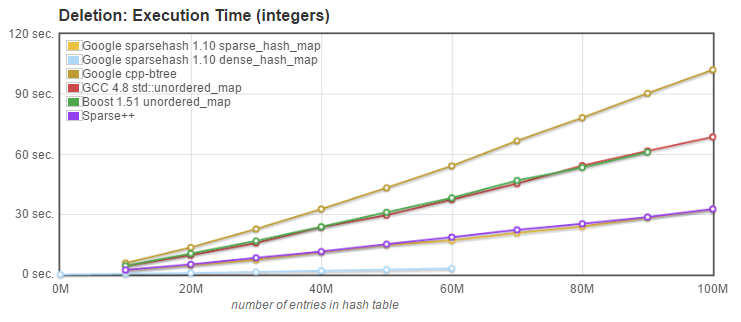
3. Delete: we measured the time needed to delete the N entries known to be present in the array. Entries had been inserted in random order, and are deleted in a different random order. |
||||
|
API used: `size_type erase(const key_type& k);` |
||||
|
|
||||
|
 |
||||
|
|
||||
|
|
||||
|
What can we conclude from these tests? Here are my observations: |
||||
|
|
||||
|
- Until it runs out of memory at 60M entries, Google's dense_hash_map is consistently the fastest, often by a quite significant margin. |
||||
|
|
||||
|
- Both Boost and g++ unordered_maps have very similar performance, which I would qualify as average amoung the alternatives tested. |
||||
|
|
||||
|
- Google's btree_map (from cpp-btree) does not perform very well on these tests (where the fact that it maintains the ordering of entries is not used). While it is competitive with the sparse_hash_map for insertion, the lookup time is typically at least 3 time higher than the slowest hash map, and deletion is slower as well. This is not unexpected as the btree complexity on insert, lookup and delete is O(log n). |
||||
|
|
||||
|
- Google's sparse_hash_map is very competitive, as fast as the std::unordered_maps on lookup, faster at deletion, but slower on insert. Considering its excellent memory usage characteristics, I would say it is the best compromise. |
||||
|
|
||||
|
So, if we are looking for a non-ordered associative container on linux[^1], I think the two Google offerings are most attractive: |
||||
|
|
||||
|
- Google's dense_hash_map: **extremely fast, very high memory requirement** (unless the maximum numbers of entries is known in advance, and is not just a little bit greater than a power of two). |
||||
|
|
||||
|
- Google's sparse_hash_map: **very memory efficient, fast lookup and deletion**, however slower that std::unordered_map on insertion. |
||||
|
|
||||
|
|
||||
|
### Introducing [Sparsepp](https://github.com/greg7mdp/sparsepp) |
||||
|
|
||||
|
At this point, I started wondering about the large speed difference between the sparse and dense hash_maps by Google. Could that performance gap be reduced somewhat? After all, both use [open adressing](https://en.wikipedia.org/wiki/Open_addressing) with internal [quadratic probing](https://en.wikipedia.org/wiki/Quadratic_probing). |
||||
|
|
||||
|
I was also intrigued by the remarkable sparse_hash_map memory efficiency, and wanted to fully understand its implementation, which is based on a [sparsetable](http://htmlpreview.github.io/?https://github.com/sparsehash/sparsehash/blob/master/doc/implementation.html). |
||||
|
|
||||
|
As I read the code and followed it under the debugger, I started having ideas on how to speed-up the sparse_hash_map, without significantly increasing the memory usage. That little game was addictive, and I found myself trying various ideas: some which provided significant benefits, and some that didn't pan out. |
||||
|
|
||||
|
Regardless, after a few months of work on evenings and week-ends, I am proud to present [Sparsepp](https://github.com/greg7mdp/sparsepp), a heavily modified version of Google's sparse_hash_map which offers significant performance improvements, while maintaining a a very low memory profile. |
||||
|
|
||||
|
The graphs below show the relative performance (purple line) of the [Sparsepp](https://github.com/greg7mdp/sparsepp) sparse_hash_map compared to the other implementations: |
||||
|
|
||||
|
`Note: "Sparse++" in the graphs legend is actually "Sparsepp".` |
||||
|
|
||||
|
1. Random Insert: [Sparsepp](https://github.com/greg7mdp/sparsepp), while still slower than the dense_hash_map, is significantly faster than the original sparse_hash_map and the btree_map, and as fast as the two std::unordered_map implementations. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
2. Random Lookup (find): [Sparsepp](https://github.com/greg7mdp/sparsepp) is faster than all other alternatives, except for dense_hash_map. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
3. Delete (erase): [Sparsepp](https://github.com/greg7mdp/sparsepp) is again doing very well, outperformed only by dense_hash_map. We should note that unlike the original sparse_hash_map, [Sparsepp](https://github.com/greg7mdp/sparsepp)'s sparse_hash_map does release the memory on erase, instead of just overwriting the memory with the deleted key value. Indeed, the non-standard APIs set_deleted_key() and set_empty_key(), while still present for compatibility with the original sparse_hash_map, are no longer necessary or useful. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
|
||||
|
Looks good, but what is the cost of using [Sparsepp](https://github.com/greg7mdp/sparsepp) versus the original sparse_hash_map in memory usage: |
||||
|
|
||||
|
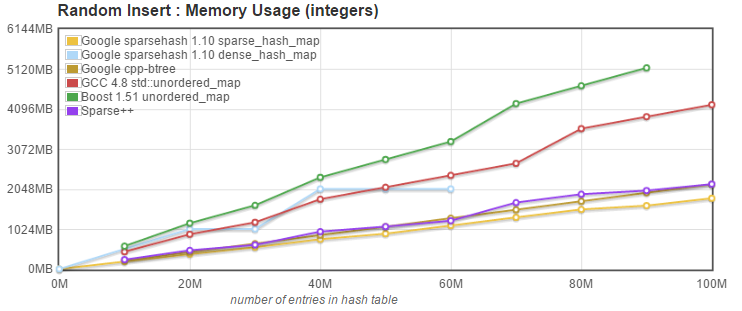 |
||||
|
|
||||
|
Not bad! While [Sparsepp](https://github.com/greg7mdp/sparsepp) memory usage is a little bit higher than the original sparse_hash_map, it is still memory friendly, and there are no memory spikes when the map resizes. We can see that when moving from 60M entries to 70M entries, both Google's dense and [Sparsepp](https://github.com/greg7mdp/sparsepp) hash_maps needed a resize to accomodate the 70M elements. The resize proved fatal for the dense_hash_map, who could not allocate the 6GB needed for the resize + copy, while the [Sparsepp](https://github.com/greg7mdp/sparsepp) sparse_hash_map had no problem. |
||||
|
|
||||
|
In order to validate that the sparse hash tables can indeed grow to accomodate many more entries than regular hash tables, we decided to run a test that would gounsert items until all tables run out of memory, the result of which is presented in the two graphs below: |
||||
|
|
||||
|
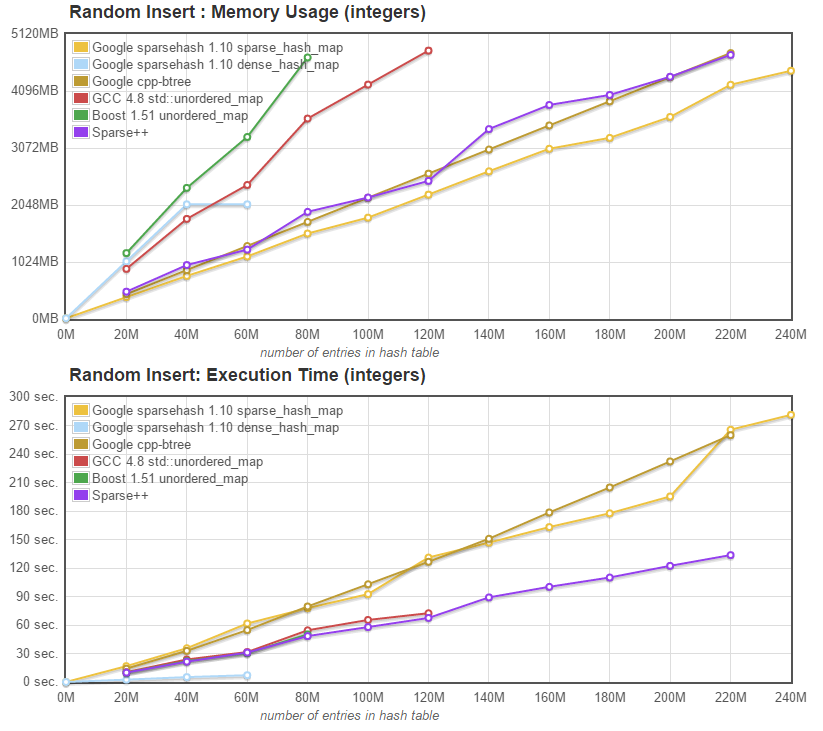 |
||||
|
|
||||
|
The table below display the maximum number of entries that could be added to each map before it ran out of memory. As a reminder, the VM had 5.7GB free before each test, and each entry is 16 bytes. |
||||
|
|
||||
|
Max entries | Google's dense_hash | Boost unordered | g++ unordered | Google's btree_map | Sparsepp | Google's sparse_hash |
||||
|
------------ | -------------- | --------------- | -------------- | --------- | -------- | --------------- |
||||
|
in millions | 60 M | 80 M | 120 M | 220 M | 220 M | 240 M |
||||
|
|
||||
|
|
||||
|
Both sparse hash implementations, as well as Google's btree_map are significantly more memory efficient than the classic unordered_maps. They are also significantly slower that [Sparsepp](https://github.com/greg7mdp/sparsepp). |
||||
|
|
||||
|
If we are willing to sacrifice a little bit of insertion performance for improved memory efficiency, it is easily done with a simple change in [Sparsepp](https://github.com/greg7mdp/sparsepp) header file `sparsepp.h`. Just change: |
||||
|
|
||||
|
`#define SPP_ALLOC_SZ 0` |
||||
|
|
||||
|
to |
||||
|
|
||||
|
`#define SPP_ALLOC_SZ 1` |
||||
|
|
||||
|
With this change, we get the graphs below: |
||||
|
|
||||
|
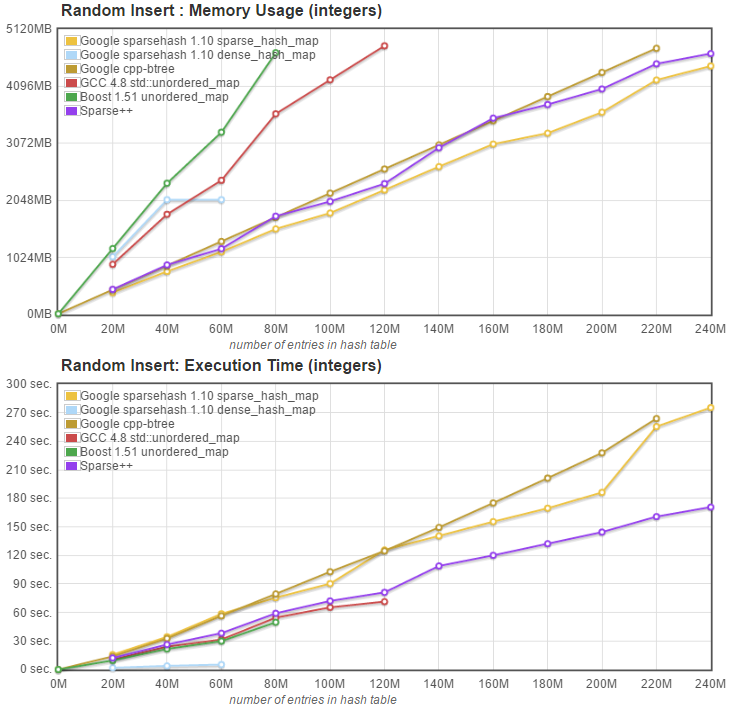 |
||||
|
|
||||
|
Now the memory usage of [Sparsepp](https://github.com/greg7mdp/sparsepp) is reduced to just a little bit more than Google's sparse_hash_map, and both sparse map implementations are able to insert 240 Million entries, but choke at 260 Million. [Sparsepp](https://github.com/greg7mdp/sparsepp) is a little bit slower on insert, but still significantly faster than Google's sparse_hash_map. Lookup performance (not graphed) is unchanged. |
||||
|
|
||||
|
To conclude, we feel that [Sparsepp](https://github.com/greg7mdp/sparsepp) provides an unusual combination of performance and memory economy, and will be a useful addition to every developer toolkit. |
||||
|
|
||||
|
Here are some other features of [Sparsepp](https://github.com/greg7mdp/sparsepp) you may find attractive: |
||||
|
|
||||
|
* Single header implementation: the full [Sparsepp](https://github.com/greg7mdp/sparsepp) resides in the single header file sparsepp.h. Just copy this file in your project, #include it, and you are good to go. |
||||
|
|
||||
|
* C++11 compatible: move semantics, cbegin()/cend(), stateful allocators |
||||
|
|
||||
|
|
||||
|
### Benchmarks code |
||||
|
|
||||
|
```c++ |
||||
|
template <class T> |
||||
|
void _fill(vector<T> &v) |
||||
|
{ |
||||
|
srand(1); // for a fair/deterministic comparison |
||||
|
for (size_t i = 0, sz = v.size(); i < sz; ++i) |
||||
|
v[i] = (T)(i * 10 + rand() % 10); |
||||
|
} |
||||
|
|
||||
|
template <class T> |
||||
|
void _shuffle(vector<T> &v) |
||||
|
{ |
||||
|
for (size_t n = v.size(); n >= 2; --n) |
||||
|
std::swap(v[n - 1], v[static_cast<unsigned>(rand()) % n]); |
||||
|
} |
||||
|
|
||||
|
template <class T, class HT> |
||||
|
double _fill_random(vector<T> &v, HT &hash) |
||||
|
{ |
||||
|
_fill<T>(v); |
||||
|
_shuffle<T>(v); |
||||
|
|
||||
|
double start_time = get_time(); |
||||
|
|
||||
|
for (size_t i = 0, sz = v.size(); i < sz; ++i) |
||||
|
hash.insert(typename HT::value_type(v[i], 0)); |
||||
|
return start_time; |
||||
|
} |
||||
|
|
||||
|
template <class T, class HT> |
||||
|
double _lookup(vector<T> &v, HT &hash, size_t &num_present) |
||||
|
{ |
||||
|
_fill_random(v, hash); |
||||
|
|
||||
|
num_present = 0; |
||||
|
size_t max_val = v.size() * 10; |
||||
|
double start_time = get_time(); |
||||
|
|
||||
|
for (size_t i = 0, sz = v.size(); i < sz; ++i) |
||||
|
{ |
||||
|
num_present += (size_t)(hash.find(v[i]) != hash.end()); |
||||
|
num_present += (size_t)(hash.find((T)(rand() % max_val)) != hash.end()); |
||||
|
} |
||||
|
return start_time; |
||||
|
} |
||||
|
|
||||
|
template <class T, class HT> |
||||
|
double _delete(vector<T> &v, HT &hash) |
||||
|
{ |
||||
|
_fill_random(v, hash); |
||||
|
_shuffle(v); // don't delete in insertion order |
||||
|
|
||||
|
double start_time = get_time(); |
||||
|
|
||||
|
for(size_t i = 0, sz = v.size(); i < sz; ++i) |
||||
|
hash.erase(v[i]); |
||||
|
return start_time; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
[^1]: Google's hash maps were most likely developed on linux/g++. When built on Windows with Visual Studio (2015), the lookup of items is very slow, to the point that the sparse hashtable is not much faster than Google's btree_map (from the cpp-btree library). The reason for this poor performance is that Google's implementation uses by default the hash functions provided by the compiler, and those provided by the Visual C++ compiler turn out to be very inefficient. If you are using Google's sparse_hash_map on Windows, you can look forward to an even greater performance increase when switching to [Sparsepp](https://github.com/greg7mdp/sparsepp). |
||||
|
|
||||
|
|
||||
|
|
||||
@ -0,0 +1,47 @@ |
|||||
|
# Windows image file caches |
||||
|
Thumbs.db |
||||
|
ehthumbs.db |
||||
|
|
||||
|
# Folder config file |
||||
|
Desktop.ini |
||||
|
|
||||
|
# Recycle Bin used on file shares |
||||
|
$RECYCLE.BIN/ |
||||
|
|
||||
|
# Windows Installer files |
||||
|
*.cab |
||||
|
*.msi |
||||
|
*.msm |
||||
|
*.msp |
||||
|
|
||||
|
# Windows shortcuts |
||||
|
*.lnk |
||||
|
|
||||
|
# ========================= |
||||
|
# Operating System Files |
||||
|
# ========================= |
||||
|
|
||||
|
# OSX |
||||
|
# ========================= |
||||
|
|
||||
|
.DS_Store |
||||
|
.AppleDouble |
||||
|
.LSOverride |
||||
|
|
||||
|
# Thumbnails |
||||
|
._* |
||||
|
|
||||
|
# Files that might appear in the root of a volume |
||||
|
.DocumentRevisions-V100 |
||||
|
.fseventsd |
||||
|
.Spotlight-V100 |
||||
|
.TemporaryItems |
||||
|
.Trashes |
||||
|
.VolumeIcon.icns |
||||
|
|
||||
|
# Directories potentially created on remote AFP share |
||||
|
.AppleDB |
||||
|
.AppleDesktop |
||||
|
Network Trash Folder |
||||
|
Temporary Items |
||||
|
.apdisk |
||||
@ -0,0 +1,11 @@ |
|||||
|
all: spp_test |
||||
|
|
||||
|
clean: |
||||
|
/bin/rm spp_test |
||||
|
|
||||
|
test: |
||||
|
./spp_test |
||||
|
|
||||
|
spp_test: spp_test.cc sparsepp.h makefile |
||||
|
$(CXX) -O2 -std=c++0x -D_CRT_SECURE_NO_WARNINGS spp_test.cc -o spp_test |
||||
|
|
||||
5626
resources/3rdparty/sparsepp/sparsepp.h
File diff suppressed because it is too large
View File
File diff suppressed because it is too large
View File
2923
resources/3rdparty/sparsepp/spp_test.cc
File diff suppressed because it is too large
View File
File diff suppressed because it is too large
View File
@ -0,0 +1,280 @@ |
|||||
|
// ---------------------------------------------------------------------- |
||||
|
// Copyright (c) 2016, Steven Gregory Popovitch - greg7mdp@gmail.com |
||||
|
// All rights reserved. |
||||
|
// |
||||
|
// Code derived derived from Boost libraries. |
||||
|
// Boost software licence reproduced below. |
||||
|
// |
||||
|
// Redistribution and use in source and binary forms, with or without |
||||
|
// modification, are permitted provided that the following conditions are |
||||
|
// met: |
||||
|
// |
||||
|
// * Redistributions of source code must retain the above copyright |
||||
|
// notice, this list of conditions and the following disclaimer. |
||||
|
// * Redistributions in binary form must reproduce the above |
||||
|
// copyright notice, this list of conditions and the following disclaimer |
||||
|
// in the documentation and/or other materials provided with the |
||||
|
// distribution. |
||||
|
// * The name of Steven Gregory Popovitch may not be used to |
||||
|
// endorse or promote products derived from this software without |
||||
|
// specific prior written permission. |
||||
|
// |
||||
|
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS |
||||
|
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT |
||||
|
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR |
||||
|
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT |
||||
|
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, |
||||
|
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT |
||||
|
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, |
||||
|
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY |
||||
|
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT |
||||
|
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE |
||||
|
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. |
||||
|
// ---------------------------------------------------------------------- |
||||
|
|
||||
|
// --------------------------------------------------------------------------- |
||||
|
// Boost Software License - Version 1.0 - August 17th, 2003 |
||||
|
// |
||||
|
// Permission is hereby granted, free of charge, to any person or organization |
||||
|
// obtaining a copy of the software and accompanying documentation covered by |
||||
|
// this license (the "Software") to use, reproduce, display, distribute, |
||||
|
// execute, and transmit the Software, and to prepare derivative works of the |
||||
|
// Software, and to permit third-parties to whom the Software is furnished to |
||||
|
// do so, all subject to the following: |
||||
|
// |
||||
|
// The copyright notices in the Software and this entire statement, including |
||||
|
// the above license grant, this restriction and the following disclaimer, |
||||
|
// must be included in all copies of the Software, in whole or in part, and |
||||
|
// all derivative works of the Software, unless such copies or derivative |
||||
|
// works are solely in the form of machine-executable object code generated by |
||||
|
// a source language processor. |
||||
|
// |
||||
|
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
||||
|
// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, |
||||
|
// FITNESS FOR A PARTICULAR PURPOSE, TITLE AND NON-INFRINGEMENT. IN NO EVENT |
||||
|
// SHALL THE COPYRIGHT HOLDERS OR ANYONE DISTRIBUTING THE SOFTWARE BE LIABLE |
||||
|
// FOR ANY DAMAGES OR OTHER LIABILITY, WHETHER IN CONTRACT, TORT OR OTHERWISE, |
||||
|
// ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER |
||||
|
// DEALINGS IN THE SOFTWARE. |
||||
|
// --------------------------------------------------------------------------- |
||||
|
|
||||
|
// ---------------------------------------------------------------------- |
||||
|
// H A S H F U N C T I O N S |
||||
|
// ---------------------------- |
||||
|
// |
||||
|
// Implements spp::spp_hash() and spp::hash_combine() |
||||
|
// |
||||
|
// The exact same code is duplicated in sparsepp.h. |
||||
|
// |
||||
|
// WARNING: Any change here has to be duplicated in sparsepp.h. |
||||
|
// ---------------------------------------------------------------------- |
||||
|
|
||||
|
#if !defined(spp_utils_h_guard_) |
||||
|
#define spp_utils_h_guard_ |
||||
|
|
||||
|
#if defined(_MSC_VER) |
||||
|
#if (_MSC_VER >= 1600 ) // vs2010 (1900 is vs2015) |
||||
|
#include <functional> |
||||
|
#define SPP_HASH_CLASS std::hash |
||||
|
#else |
||||
|
#include <hash_map> |
||||
|
#define SPP_HASH_CLASS stdext::hash_compare |
||||
|
#endif |
||||
|
#if (_MSC_FULL_VER < 190021730) |
||||
|
#define SPP_NO_CXX11_NOEXCEPT |
||||
|
#endif |
||||
|
#elif defined(__GNUC__) |
||||
|
#if defined(__GXX_EXPERIMENTAL_CXX0X__) || (__cplusplus >= 201103L) |
||||
|
#include <functional> |
||||
|
#define SPP_HASH_CLASS std::hash |
||||
|
|
||||
|
#if (__GNUC__ * 10000 + __GNUC_MINOR__ * 100) < 40600 |
||||
|
#define SPP_NO_CXX11_NOEXCEPT |
||||
|
#endif |
||||
|
#else |
||||
|
#include <tr1/unordered_map> |
||||
|
#define SPP_HASH_CLASS std::tr1::hash |
||||
|
#define SPP_NO_CXX11_NOEXCEPT |
||||
|
#endif |
||||
|
#elif defined __clang__ |
||||
|
#include <functional> |
||||
|
#define SPP_HASH_CLASS std::hash |
||||
|
|
||||
|
#if !__has_feature(cxx_noexcept) |
||||
|
#define SPP_NO_CXX11_NOEXCEPT |
||||
|
#endif |
||||
|
#else |
||||
|
#include <functional> |
||||
|
#define SPP_HASH_CLASS std::hash |
||||
|
#endif |
||||
|
|
||||
|
#ifdef SPP_NO_CXX11_NOEXCEPT |
||||
|
#define SPP_NOEXCEPT |
||||
|
#else |
||||
|
#define SPP_NOEXCEPT noexcept |
||||
|
#endif |
||||
|
|
||||
|
#define SPP_INLINE |
||||
|
|
||||
|
#ifndef SPP_NAMESPACE |
||||
|
#define SPP_NAMESPACE spp |
||||
|
#endif |
||||
|
|
||||
|
namespace SPP_NAMESPACE |
||||
|
{ |
||||
|
|
||||
|
template <class T> |
||||
|
struct spp_hash |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(const T &__v) const SPP_NOEXCEPT |
||||
|
{ |
||||
|
SPP_HASH_CLASS<T> hasher; |
||||
|
return hasher(__v); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
template <class T> |
||||
|
struct spp_hash<T *> |
||||
|
{ |
||||
|
static size_t spp_log2 (size_t val) SPP_NOEXCEPT |
||||
|
{ |
||||
|
size_t res = 0; |
||||
|
while (val > 1) |
||||
|
{ |
||||
|
val >>= 1; |
||||
|
res++; |
||||
|
} |
||||
|
return res; |
||||
|
} |
||||
|
|
||||
|
SPP_INLINE size_t operator()(const T *__v) const SPP_NOEXCEPT |
||||
|
{ |
||||
|
static const size_t shift = spp_log2(1 + sizeof(T)); |
||||
|
return static_cast<size_t>((*(reinterpret_cast<const uintptr_t *>(&__v))) >> shift); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<bool> : public std::unary_function<bool, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(bool __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<char> : public std::unary_function<char, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(char __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<signed char> : public std::unary_function<signed char, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(signed char __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<unsigned char> : public std::unary_function<unsigned char, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(unsigned char __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<wchar_t> : public std::unary_function<wchar_t, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(wchar_t __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<short> : public std::unary_function<short, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(short __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<unsigned short> : public std::unary_function<unsigned short, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(unsigned short __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<int> : public std::unary_function<int, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(int __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<unsigned int> : public std::unary_function<unsigned int, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(unsigned int __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<long> : public std::unary_function<long, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(long __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<unsigned long> : public std::unary_function<unsigned long, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(unsigned long __v) const SPP_NOEXCEPT {return static_cast<size_t>(__v);} |
||||
|
}; |
||||
|
|
||||
|
template <> |
||||
|
struct spp_hash<float> : public std::unary_function<float, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(float __v) const SPP_NOEXCEPT |
||||
|
{ |
||||
|
// -0.0 and 0.0 should return same hash |
||||
|
uint32_t *as_int = reinterpret_cast<uint32_t *>(&__v); |
||||
|
return (__v == 0) ? static_cast<size_t>(0) : static_cast<size_t>(*as_int); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
#if 0 |
||||
|
// todo: we should not ignore half of the double => see libcxx/include/functional |
||||
|
template <> |
||||
|
struct spp_hash<double> : public std::unary_function<double, size_t> |
||||
|
{ |
||||
|
SPP_INLINE size_t operator()(double __v) const SPP_NOEXCEPT |
||||
|
{ |
||||
|
// -0.0 and 0.0 should return same hash |
||||
|
return (__v == 0) ? (size_t)0 : (size_t)*((uint64_t *)&__v); |
||||
|
} |
||||
|
}; |
||||
|
#endif |
||||
|
|
||||
|
template <class T, int sz> struct Combiner |
||||
|
{ |
||||
|
inline void operator()(T& seed, T value); |
||||
|
}; |
||||
|
|
||||
|
template <class T> struct Combiner<T, 4> |
||||
|
{ |
||||
|
inline void operator()(T& seed, T value) |
||||
|
{ |
||||
|
seed ^= value + 0x9e3779b9 + (seed << 6) + (seed >> 2); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
template <class T> struct Combiner<T, 8> |
||||
|
{ |
||||
|
inline void operator()(T& seed, T value) |
||||
|
{ |
||||
|
seed ^= value + T(0xc6a4a7935bd1e995) + (seed << 6) + (seed >> 2); |
||||
|
} |
||||
|
}; |
||||
|
|
||||
|
template <class T> |
||||
|
inline void hash_combine(std::size_t& seed, T const& v) |
||||
|
{ |
||||
|
spp::spp_hash<T> hasher; |
||||
|
Combiner<std::size_t, sizeof(std::size_t)> combiner; |
||||
|
|
||||
|
combiner(seed, hasher(v)); |
||||
|
} |
||||
|
|
||||
|
}; |
||||
|
|
||||
|
#endif // spp_utils_h_guard_ |
||||
|
|
||||
Write
Preview
Loading…
Cancel
Save
Reference in new issue